
 Как построить кластер?
Как построить кластер?
Хорошая новость заключается в том, что развертывание кластера как такового - задача экстремально простая. Причем, для этого подойдет любой дистрибутив по вашему выбору. Какой именно из дистрибутивов Linux ставить в качестве базовой ОС - не имеет значения. Ubuntu, Mandriva, Alt Linux, Red Hat, SuSE... Выбор зависит только от ваших предпочтений.
Попытаюсь по шагам объяснить, как развернуть
кластер, используя дистрибутив общего назначения.
Итак... Вы должны будете:
- Установить операционную систему на компьютер, который будет выступать в роли консоли кластера. То есть на этом компьютере будут компилироваться и запускаться параллельные программы. Другими словами, за этим компьютером будет сидеть человек, запускать программы и смотреть, что получилось.
- После инсталлирования базовой ОС на консоли кластера, если это не сделано в процессе первоначальной установки, Вы должны будете установить необходимые компиляторы (фортран, С) и все необходимые библиотеки, desktop environment (GNOME или KDE по вашему выбору), текстовые редакторы и пр., то есть превратить этот компьютер в рабочую станцию разработчика.
- Установить из репозитория или из исходников пакет MPICH или
OpenMPI, если он Вам более по душе. Я лично предпочитаю OpenMPI.
- Описать в /etc/hosts будущие узлы вашего кластера, в том числе и консоль кластера.
- Установить NFS и расшарить для всех узлов кластера некую директорию, в которой будут размещаться исполняемые модули параллельных программ и файлы данных, которыми эти программы будут пользоваться в процессе своей работы.
- Установить на консоли кластера ssh-клиент (обязательно) и ssh-сервер (опционально, если Вы предполагаете давать доступ к консоли кластера по сети).
- На всех узлах кластера установить операционную систему, библиотеки, необходимые для выполнения пользовательских параллельных программ, установить MPICH, NFS-client, ssh-server. Узлы кластера в целях экономии ресурсов должны грузиться в runlevel 3, так что ставить туда GNOME или KDE не надо. Максимум - поставить туда гномовские или кдешные библиотеки, если они нужны пользовательским программам.
- Описать в /etc/hosts всех узлов кластера будущие узлы вашего кластера, в том числе и консоль кластера.
- На всех узлах кластера необходимо автоматом при загрузке монтировать расшаренный в п. 5 ресурс. Причем, путь к этому ресурсу должен быть одинаков, как на консоли кластера, так и на его узлах. Например, если на консоли кластера Вы расшариваете каталог /home/mpiuser/data, то на узлах кластера этот ресурс также должен быть смонтирован в /home/mpiuser/data.
- На всех узлах кластера обеспечить безпарольный доступ по ssh для
консоли кластера. Как это сделать вы можете посмотреть на моем сайте.
- Собственно, все. Кластер собран и полностью готов к использованию. Фактически для развертывания кластера нам потребовалось установить ОС, зайти в так сказать в "Установку и удаление программ", отметить для установки пакеты SSH и MPICH, запретить запрос пароля удаленного доступа к узлам кластера, расшарить на центральном узле каталог, где будут храниться наши параллельные программы и данные и поставить на узлах кластера автоматическое подключение к этому каталогу при загрузке. Как компилировать и запускать на исполнение параллельные программы Вы можете посмотреть в других разделах этого сайта и в документации к MPICH.
Как видите, все очень просто и ничего, кроме дистрибутива с репозиториями не нужно. Более подробно вопрос установки кластера на базе операционной системы Linux описан в разделе Ubuntu кластер.
Теперь я хотел бы обсудить другой вопрос, а именно построение сети кластера. Поскольку сеть - самое узкое место и от нее впрямую зависит эффективность работы кластера, то хотелось бы сделать следующее. Хотелось бы, чтобы функционирование сетевой файловой системы NFS не мешало обмену данными, который осуществляют между собой части параллельной программы, работающие на разных узлах. Чтобы это осуществить, необходимо физически разделить сеть на два сегмента. В одном сегменте будет работать NFS, в другом - будет происходить обмен данными между частями программы.
Таким образом и в консоли кластера и в его узлах необходимо иметь два сетевых интерфейса (две сетевые карты), Соответственно, нужно два набора свитчей, не связанных друг с другом, и два набора сетевых реквизитов для этих интерфейсов. То есть, NFS работает, например, в сети 192.168.1.0/24, а обмен данными происходит в сети 192.168.2.0/24. И соответственно, в файлах /etc/exports и /etc/fstab должны будут быть прописаны адреса из первой сети, а в файлах /etc/hosts и в файла machines.LINUX, описывающих кластер - адреса из второй. Что за файл machines.LINUX - смотрите в документации MPICH.
Важное замечание. Файлы, хранящиеся на диске, в условиях параллельной задачи, выполняемой на кластере, могут понадобиться только для сохранения состояния задачи в контрольных точках. Конечно, дисковые ресурсы можно использовать и для организации виртуальной памяти, подгружая по мере необходимости данные в оперативную память, увеличивая тем самым размер разностной сетки. Однако при наличии кластера, увеличение размера разностной сетки логичнее и эффективнее может быть выполнено посредством использования дополнительных вычислительных узлов кластера. Если же дисковые ресурсы используются только для сохранения контрольных точек и эти контрольные точки расположены не в каждой итерации (а в каждой десятой или сотой), то разделение локальной сети кластера на два независимых сегмента (NFS и сеть межпроцессорного обмена данных) является не обязательной. Вполне можно обойтись всего одним сегментом, используя его и для NFS и для обмена данными. Поскольку NFS будет использоваться достаточно редко, то и отрицательное влияние ее на эффективность кластера будет минимально.
Еще одно. Настоятельно рекомендуется использовать гигабитную сеть, как наиболее доступную для университета (с точки зрения финансов). Строго говоря, Gigabit Ethernet - не лучший выбор в качестве сети кластера в силу того, что эта сеть обладает достаточно большой латентностью. Но это доступное решение. Если же финансы позволят, то лучше конечно обратить внимание на Myrinet или 10Gbit Ethernet.
Далее. Параметры сети никогда не бывают слишком хорошие. Поэтому, если есть возможность, надо стараться их улучшить. Если Myrinet или 10GbE для вас будут недоступны, то можно попытаться улучшить характеристики гигабитной сети. Собственно, сделать из нее двухгигабитку! Погуглите по ключевым словам channel bonding, кроме того, у меня на сайте немного про это написано. Суть дела в том, что вместо одной сетевой карты мы используем две, объединив их специальным драйвером в единый виртуальный канал с двойной пропускной способностью. В этом случае карты должны быть подключены к двум отдельным свитчам, то есть потоки по этим картам мы разделяем так же, как мы это делали раньше, разделяя NFS и передачу данных. Создание такого канала - немного геморройное занятие, поэтому только от вашего желания и энтузиазма зависит, делать это или нет. В принципе, это не обязательно, хотя эффект будет заметный.
Теперь собственно о том, а зачем вообще Вам нужен кластер. Дело в том, что утверждение "чем больше узлов в кластере, тем быстрее он работает" - в общем случае не верно. Давайте посмотрим, в каких случаях нам захочется считать наши программы на кластере. Существует только две цели использования кластера.
- Имеется разностная сетка размера R, вычисления на которой при использовании обычного компьютера занимают время T. Время T - критический параметр. Нам хочется существенно уменьшить время вычислений, имея R как константу.
- Имеется разностная сетка размера R, вычисления на которой при использовании обычного компьютера занимают время T. Время T - не критично. Нас интересует увеличение размера сетки сверх имеющейся в одном компьютере памяти для более детального счета, возможного получения более тонких эффектов и т.п.
Все вычисления на разностной сетке имеют один общий и важный для нас параметр: время одной итерации. В случае использования кластера это время состоит из двух частей: время счета на сетке Titer и время обмена данными между узлами Texch. (Почитайте про граничный обмен на моем сайте.) Titer зависит только от мощности процессора. А вот Texch зависит уже, от размера разностной сетки, количества узлов кластера и пропускной способности сети. Я не буду приводить формул, вы их сами можете при желании вывести. (Посмотрите еще вот этот файл. Именно по нему были построены графики.) Приведу окончательный результат для случая двухгигабитной сети, размера разностной сетки 64 гигабита и времени одной итерации 100 сек.
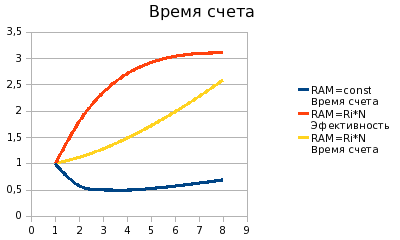
 На графике ось ординат - временная характеристика, ось абсцисс -
количество узлов кластера.
На графике ось ординат - временная характеристика, ось абсцисс -
количество узлов кластера.
Обратите внимание на синий график. Это модель первого случая, когда разбиваем разностную сетку постоянного размера на несколько узлов. Как видно из графика, время счета вначале уменьшается, при увеличении количества узлов кластера. Что мы и хотели получить. Однако уменьшение происходит до определенного предела. При количестве узлов более четырех общее время счета снова начинает расти. Происходит это из-за увеличения объема данных, пересылаемых между узлами. Таким образом получается, что при постоянном размере сетки, увеличивать размер кластера свыше четырех узлов не имеет смысла.
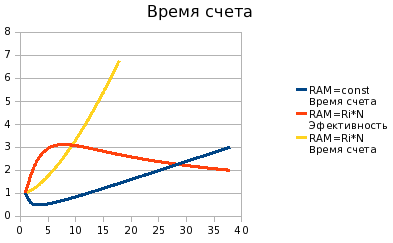
Теперь рассмотрим случай 2, когда нам важен размер сетки, а со
временем счета мы можем смириться.
Давайте представим, что у нас есть один компьютер с неограниченной
памятью. Увеличивая размер разностной сетки, мы получаем линейное (с
коэффициентом 1) увеличение время счета. Теперь сравним это время с
тем, которое получится, если мы будем считать такую же сетку, но на
кластере. Причем увеличивая размер сетки вдвое, мы увеличиваем вдвое и
количество узлов кластера. Поскольку две чати сетки обсчитываются
параллельно, то время итерации не увеличивается, но появляется время
обмена данными. Красный график
показывает отношение времени счета на одном компьютере (с
неограниченной памятью) ко времени счета такой же сетки на кластере. Желтый график показывает рост времени счета
при увеличении узлов кластера (и, соответственно, увеличении размера
сетки). И рост этот, что важно, меньше, чем линейный.
Мы видим, что время счета на кластере существенно меньше, чем если бы мы считали сетку на одном компьютере. Причем, даже при увеличении размера сетки (и узлов кластера) в 40 раз, мы, тем не менее, получаем выигрыш во времени.
Для кластерных вычислительных систем одним из широко применяемых способов построения коммуникационной среды является использование концентраторов (hub) или коммутаторов (switch) для объединения процессорных узлов кластера в единую вычислительную сеть. В этих случаях топология сети кластера представляет собой полный граф, в котором, однако, имеются определенные ограничения на одновременность выполнения коммуникационных операций. Так, при использовании концентраторов передача данных в каждый текущий момент времени может выполняться только между двумя процессорными узлами; коммутаторы могут обеспечивать взаимодействие нескольких непересекающихся пар процессоров.
Следует отметить, что приведенные выше расчеты сделаны в предположении, что для построения сети кластера используются концентраторы. В случае же использования коммутаторов скоростные характеристики кластера могут заметно улучшиться. Поэтому именно их рекомендуется использовать при проектировании кластера.
Резюме. Если мы имеем целью ускорить выполнение программы, то можно использовать кластер, но размером не больше двух-четырех узлов. Если же мы имеем целью получение доступа к памяти, большей, чем может нам обеспечить один компьютер, то кластер - именно то, что нам нужно.
Важное замечание. На приведенные на графиках зависимости очень сильно влияет такой параметр, как время счета одной итерации. То есть время между двумя моментами, когда возникает необходимость в граничном обмене. Чем оно меньше, тем хуже характеристика кластера. Если у вас достаточно простая задача, в которой время итерации порядка десятка секунд, то необходимость в кластеризации такой задачи весьма сомнительна. В любом случае, желательно, чтобы время обмена граничными данными между узлами кластера было много меньше времени итерации.
Ну и еще пару слов о целесообразности использования кластера. Дело в том, что не всякую задачу можно решать на кластере. Во-первых, как я уже говорил, если время итерации (время счета между моментами возникновения необходимости граничного обмена) достаточно мало и сравнимо с временем передачи данных, то эффективность кластера резко снижается. Во-вторых, не всякую задачу можно распараллелить. Например метод прогонки решения дифф. ур. вааще никак не распараллеливается и может быть решен только на одном процессоре.