
 Сетевая файловая система
Сетевая файловая система
 Одной из особенностей запуска MPI-программ является необходимость наличия копий программы
на всех узлах кластера, на которых она исполняется. Например, если ваши программа myprog
расположена в каталоге /home/mpiuser/program1, то на всех узлах кластера должен
присутствовать этот каталог и в него должна быть помещена ваша программа.
Одной из особенностей запуска MPI-программ является необходимость наличия копий программы
на всех узлах кластера, на которых она исполняется. Например, если ваши программа myprog
расположена в каталоге /home/mpiuser/program1, то на всех узлах кластера должен
присутствовать этот каталог и в него должна быть помещена ваша программа.
Это условие пораждает необходимость каким-либо образом распределить копии исполняемого модуля программы между узлами кластера. Аналогичное требование относится и к хранимым на диске данным, которые программа будет использовать.
Существуют различные механизмы, позволяющие выполнять подобное распределение. В большинстве случаев это разнообразные скрипты, осуществляющие синхронизацию каталогов на узлах кластера с помощью команд scp или rsync. Подобные способы синхронизации имеют свои недостатки. Например, в случае, когда различные копии программы должны обращаться к одним и тем же данным, хранимым на диске, и изменять их определенным образом, возникает проблема, связанная с необходимостью постоянной синхронизации файлов на узлах кластера. Другая проблема возникает при использовании в качестве узлов кластера бездисковых станций. В этом случае вся файловая система таких узлов хранится в оперативной памяти копьютера и чем больше мы закачиваем данных на такой узел, тем меньше остается памяти для выполнения программы.
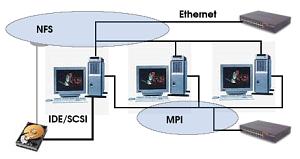
Для избавления от подобных проблем используются сетевые файловые системы. Существует большое количество реализаций таких систем, как платных, так и распространяемых под лицензией GPL. Мы с вами будем рассматривать сетевую файловую систему NFS, имеющуюся в любом Linux-дистрибутиве общего назначения. Файловая система NFS - это аналог того, что продуктах Майкрософт известно под названием windows share.
Сетевая файловая система NFS состоит из двух компонентов: сервера и клиента. Сервер осуществляет сетевой доступ к каталогам базовой файловой системы на основе определенных правил разграничения доступа. Клиент используется для подключения к расшаренным ресурсам. Установку NFS мы рассматривать не будем, поскольку она достаточно тривиальна. Вы либо в процессе исталляции операционной системы указываете необходимость установки NFS, либо вручную устанавливаете два пакета rpm: nsf-server и nfs_clients. Далее мы рассмотрим процесс конфигурации сетевой файловой системы.
Конфигурация сервера.
Для обеспечения сетевого доступа узлов кластера к расшаренным на сервере кластера ресурсам необходимо вначале разрешить подключение nfs-клиентам к nfs-серверу. Далее будем предполагать, что узлы кластера имеют ip-адреса в диапазоне 192.168.1.2-192.168.1.254. Консоль кластера, к каталогам файловой системы которой мы будем подключаться через NFS, имеет ip-адрес 192.618.1.1. Для разрешения сетевого доступа к NFS с этих адресов мы в файле /etc/hosts.allow прописываем следующую строчку:
portmap: 192.168.1.
Точка в конце строки обязательна! Далее мы должны определить к какому каталогу мы разрешаем сетевой доступ. То есть, какой каталог расшариваем. К примеру, мы хотим обеспечить узлам кластера доступ в каталог /home/mpiuser/data-and-progs. Для этого в файле /etc/exports прописываем строку:
/home/mpiuser/data-and-progs 192.168.1.0/255.255.255.0(rw,no_root_squash)
На этом настройка серверной части закончена. Чтобы изменения вступили в силу необходимо перезапустить службу NFS с помощью команды "service portmap restart".
Конфигурация клиентов.
Переходим от сервера кластара (консоли кластера) к остальным узлам. Все что будет описано ниже необходимо выполнить на каждом компьютере кластера кроме консольного.
Для подключения любой файловой системы (дискеты, раздела диска, сетевого ресурса) используется команда mount, если подключение происходит вручную, или запись в файле /etc/fstab, если подключение происходит в момент загрузки системы. Нас будет интересовать последний случай.
Для обеспечения запуска mpi-программ нам нужно, чтобы содержимое каталога /home/mpiuser/data-and-progs на узлах кластера совпадало с содержимым этого же каталога на консоли кластера. Для этого мы должны в домашнем каталоге пользователь mpiuser (/home/mpiuser) создать пустой каталог data-and-progs. После чего прописать в файле /etc/fstab следующую строку:
192.168.1.1:/home/mpiuser/data-and-progs /home/mpiuser/data-and-progs nfs rw 0 0
Чтобы удаленный (сетевой) каталог монтировался автоматически при загрузке узла кластера, сервис клиента NFS должен запускаться в процедуре начальной загрузки.
На этом установка сетевой кластерной файловой системы завершена. При включении кластера, консоль кластера должна быть загружена до того, как вы начнете включать остальные узлы.
Разделение сетей.
Поскольку сеть является самым узким местом кластера, желательно организовать работу так, чтобы операции межпроцессорной пересылки данных не пересекались с файловыми операциями NFS. Для этого необходимо компьютеры кластера оснастить дополнительными сетевыми картами, объединенными в отдельную сеть, физически не пересекающуюся с первыми картами. То есть использовать дополнительный набор хабов или свитчей. Сетевой интерфейс на вторых картах должен иметь ip-адреса, из другой, отличной от первого интерфейса сети. Например, на сервере кластера сетевая карта, через которую будет осуществляться доступ к расшаренному каталогу имеет адрес 192.168.1.1, а карта, через которую будет происходить межпроцессорное взаимодействие, имеет адрес 192.168.2.1.
Таким образом, NFS мы настраиваем так, как это было описано выше, а при конфигурировании MPI, список узлов кластера составляем из ip-адресов 192.168.2.*.
Естественно, разделение сетей не необходимо, но желательно.
Важное замечание. Файлы, хранящиеся на диске, в условиях параллельной задачи, выполняемой на кластере, могут понадобиться только для сохранения состояния задачи в контрольных точках. Конечно, дисковые ресурсы можно использовать и для организации виртуальной памяти, подгружая по мере необходимости данные в оперативную память, увеличивая тем самым размер разностной сетки. Однако при наличии кластера, увеличение размера разностной сетки логичнее и эффективнее может быть выполнено посредством использования дополнительных вычислительных узлов кластера. Если же дисковые ресурсы используются только для сохранения контрольных точек и эти контрольные точки расположены не в каждой итерации (а в каждой десятой или сотой), то разделение локальной сети кластера на два независимых сегмента (NFS и сеть межпроцессорного обмена данных) является не обязательной. Вполне можно обойтись всего одним сегментом, используя его и для NFS и для обмена данными. Поскольку NFS будет использоваться достаточно редко, то и отрицательное влияние ее на эффективность кластера будет минимально.