
 Как быстро построить кластер?
Как быстро построить кластер?
Вполне представима ситуация, когда по каким-либо причинам развернуть стационарный кластер не представляется возможным. Ну, например, когда компьютерный класс, который вы собираетесь использовать в качестве вычислительного кластера, по каким-то причинам обязательно должен работать под операционной системой Windows. Ничего страшного! С помощью специализированного дистрибутива PelicanHPC GNU Linux вы в любой момент, например после окончания рабочего дня и занятий в компьютерном классе, можете запустить кластер и на приведение его в боевую готовность потребуется не более пяти минут. Причем исходная операционная система, программное обеспечение и данные на используемых в качестве кластера компьютерах не будет модифицировано. После выключения кластера компьютеры придут в то состояние, которое было до начала работы кластера.
Для развертывания такого виртуального кластера вам потребуется один компакт-диск с последней версией дистрибутива PelicanHPC GNU Linux, iso-образ которого вы можете взять отсюда. С этого диска вы загружаете операционную систему кластера (не устанавливая ее на винчестер) на компьютере, который будет играть роль консоли кластера, то есть того компьютера, непосредсвенно за которым вы будете работать, компилируя и запуская ваши параллельные программы.
Остальные узлы кластера будут загружаться по сети. Для загрузки ОС вычислительных узлов кластера по сети необходимо, чтобы сетевые карты этих компьютеров умели выполнять загрузку по сети. Большинство современных карт, в том числе встроенных, это делать умеют. Если же вам не повезло, то вы всегда можете сделать загрузочный CD из образа gpxe.iso и загрузить ваши вычислительные узлы с этого CD. Если же вам совсем не повезло и на предполагаемых вычислительных узлах отсутствуют и возможность загрузки по сети и CD-приводы, то и в этом случае отчаиваться не стоит. Посетите ресурс www.rom-o-matic.net, сгенерируйте и запишите на дискету загрузочный floppy-образ, соответствующий вашим сетевым картам. С этой дискеты и выполните загрузку ОС на остальных узлах кластера.
Теперь посмотрим, как на практике выполняется загрузка кластера.
- Загружаем консоль кластера с PelicanHPC GNU Linux Live CD

- Через некоторое время повяляется следующий запрос:
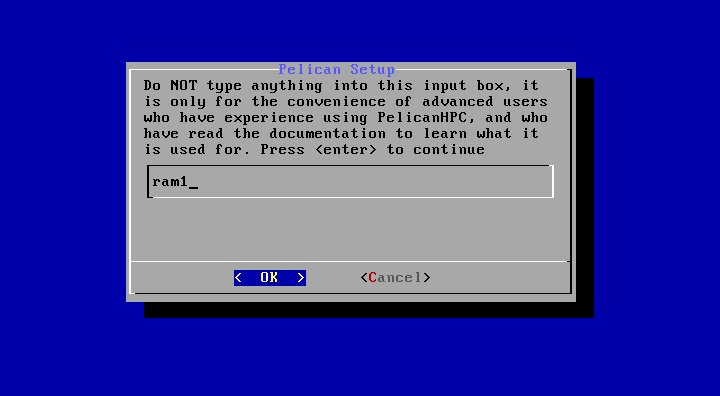
Здесь вы должны будете указать устройство, на котором будет располагаться пользовательский каталог. То есть ваш рабочий каталог, где будут храниться ваши программы, исходники и файлы данных. По умолчанию вам предложен раздел на виртуальном диске, расположенном в оперативной памяти. Это самый простой вариант, однако не самый удобный в том смысле, что после выключения компьютера все данные на этом диске будут уничтожены. В этом случае вам придется каждый раз перед выключением сохранять ваши данные на внешний носитель, например на флешку. Более удобным будет, если вы выделите на винчестере компьютера отдельный раздел для ваших данных. Как вариант может рассматриваться подключение внешнего носителя (флешки либо USB-винчестера). В таком случае вместо предложенного ram1 вы должны будуте указать что-то типа hda7, sda5, sdb1 и т.д. в зависимости от конфигурации вашей машины и выбранного варианта. - Следующий вопрос, который будет вам задан, выглядит так:
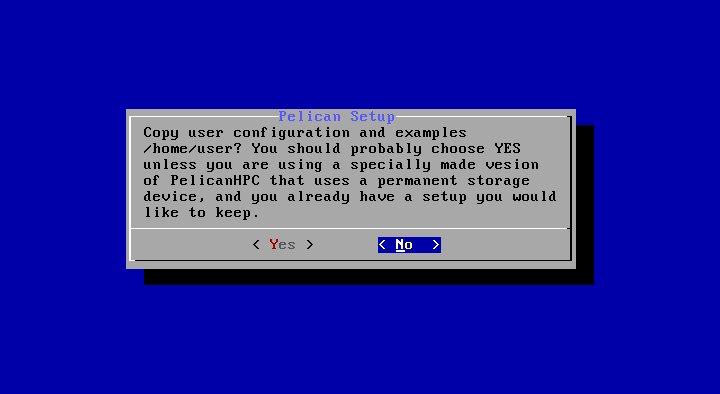
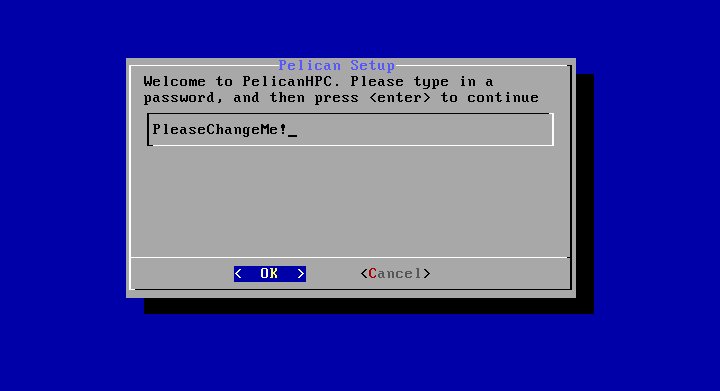
Система спрашивает, будет ли выполнена начальная конфигурация пользовательского каталога. В случае, когда вы используете в качестве пользовательского каталога виртуальный диск ram1, всегда отвечайте "Yes". Если же вы выбрали в качестве месторасположения пользовательского каталога постянный носитель (раздел винчестера компьютера, флешку или внешний USB-винчестер), тогда ответ "Yes" вы должны будете выбрать только в самый первый раз. Во все последующие загрузки кластера необходимо выбрать ответ "No". - На следующем шаге вы должны будете указать пароль пользователя, с которым вы будете подключаться в систему:
- После задания пароля вам будет предложен стандартный экран входа в систему:
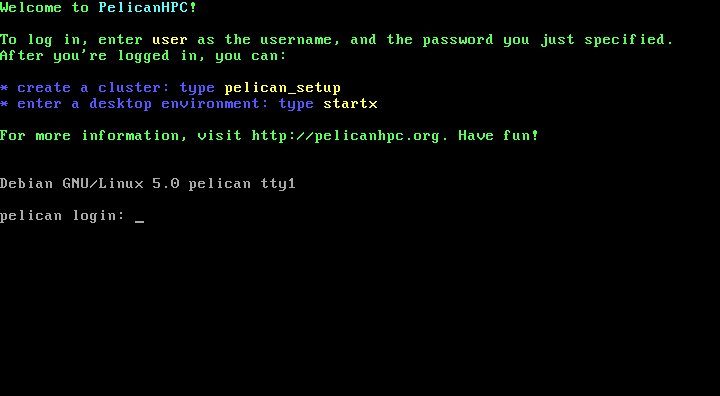
Для входа в систему вы можете использовать логин "user" и пароль, который вы определили на предыдущем шаге. - Итак, мы вошли в систему консоли кластера. Теперь нам необходимо подключить к класетру все наши вычислительные узлы.
Для этого запустим команду конфигурации кластера pelican_setup. Первое, что спросит эта команда - будем ли мы
конфигурировать сетевую загрузку вычислительный узлов?
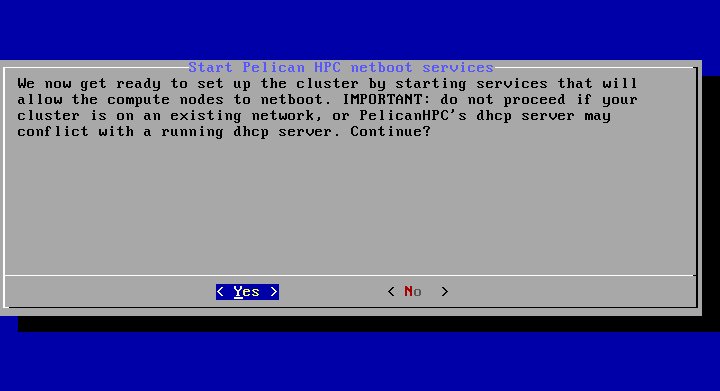
Естественно, мы говорим "Yes". - Сконфигурировав сервер сетевой загрузки, программа предложит нам выполнить загрузку всех стальных узлов кластера:
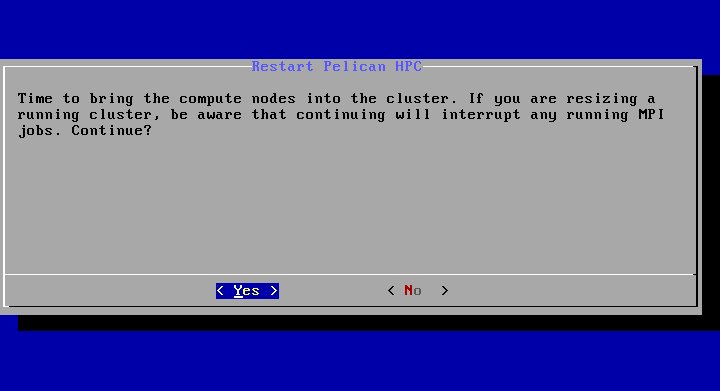
В этот момент мы должны включить все остальные компьютеры кластера, не забыв поправить настроики BIOS таким образом, чтобы они выполнили загрузку по сети. Вмешательства в процесс загрузки вычислительных узлов кластера не требуется. Надо просто дождаться, когда они все закончат процедуру загрузки, о чем будет свидетельствовать следующая картинка на экранах этих конмпьютеров: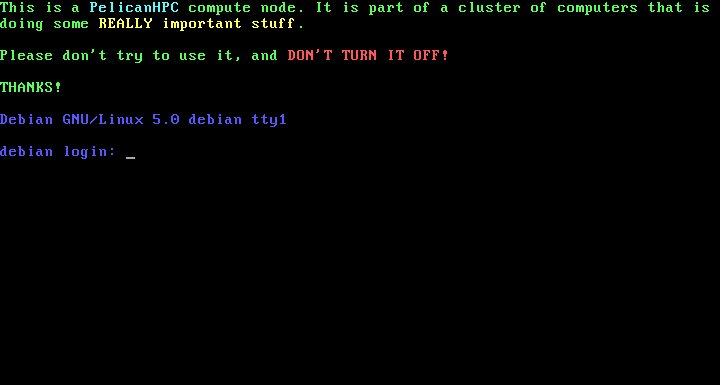
После того, как все компьютеры будут загружены, нажимаем кнопку "Yes". - Далее программа настройки попытается найти все загруженные компьютеры и включить их в конфигурацию кластера.
После выполнения этого действия она выдаст на экран итоговый результат:
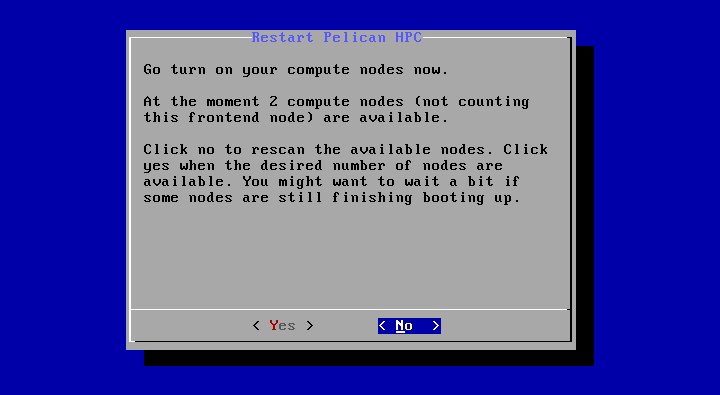
На этом экране программа сообщает нам, сколько было найдено вычислительных узлов (в данном случае два) кроме узла, который является консолью кластера. Если все нормально - нажимаем "Yes". - И, наконец, программа конфигурации кластера сообщает нам, что все настройки выполнены и кластер готов к эксплуатации:
Нам остается только завершить ее, нажав "ОК". - В некоторых случаях у меня конфигурация кластера завершалась с ошибкой, поэтому я рекомендую следующим шагом запустить скрипт реконфигурации: pelican_restart_hpc, тем самым повторив заново пункты 7-9.
Теперь кластер работоспособен. проверим его работу на тестовой программе.
Возьмем в качестве пример программу вычисления числа  flops.f. Каким-либо способом копируем исходник этой программы в пользовательский каталог
на консоли кластера. Далее выполняем следующие действия:
flops.f. Каким-либо способом копируем исходник этой программы в пользовательский каталог
на консоли кластера. Далее выполняем следующие действия:
- Компилируем программу в параллельной среде MPI с помощью команды mpif77 flops.f -o flops
- Запускаем программу на одном процессоре командой ./flops
- Запускаем программу на двух процессорах командой mpirun n2,0 ./flops
Как видно из результатов работы программы
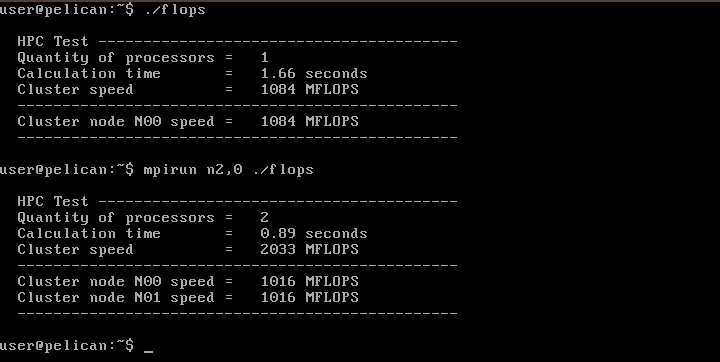
скорость вычисления на двух процессорах примерно в два раза больше, чем на одном. То есть кластер делает именно то, что мы и ожидали.
Важное замечание. По каким-то причинам конфигурация кластера оформляется таким образом, что в списке вычислительных узлов консоль кластера прописывается последней. Однако логично ожидать, что вывод программы будет идти на монитор той машины, с которой она запущена, то есть на консоль. В то же время параллельные программы обычно пишут таким образом, что весь вывод идет в процессе, который работает на самом первом узле. Поэтому при запуске программы приходится явно указывать последовательность узлов, на которых она будет выполнятся. И первым в этом списке должна быть именно консоль кластера. В нашем примере кластер состоял из трех машин. Нумерация их начинается с нуля. То есть 0, 1, 2. Поэтому мы явно указали, что первая машина - это машина номер 2 (последняя в конфигурационном списке). Указали мы это параметром n2,0, то есть программа запускалась на машине N2 и машине N0.
Если бы мы сделали кластер например из 16 машин, то их номера были бы 0, 1, 2, ... 14, 15. Для запуска нашей тестовой программы
на таком кластере надо было бы использовать команду
mpirun n15,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14 ./flops
или в сокращенном варианте
mpirun n15,0-14 ./flops