
 Тестовая параллельная задача
Тестовая параллельная задача
Для начала приведем текст параллельного варианта программы, которая будет исполнятся (частично) на графическом процессоре.
Подпрограмма iteration, выполняющая итерационный цикл расчетов будет модифицирована нами таким образом, чтобы вычисления велись только на одной строке разностной сетки. Таким образом разные строки будут обрабатываться различными параллельными процессами. Далее подробно опишем процесс распараллеливания программы.
В строках 7 и 8 мы определяем сколько будет задействовано ядер (BLOCKS) графического процессора и сколько потоков (THREADS) будет запущено в каждом ядре. Эти константы мы определяем таким образом, чтобы общее количество запущенных процессов (BLOCKS·THREADS) равнялось размерности нашей разностной сетки по оси Y.
Первое отличие заключается в том, что подпрограмма, выполняемая на графическом процессоре, не может возвращать значения, поэтому ее придется немного переделать. Для начала с помощью модификатора __global__ объявим подпрограмму, как исполняемую на GPU. Далее, поскольку в последовательной версии программы подпрограмма iteration возвращала вычисленную максимальную для всей разностной сетки дельту, а в данном случае мы этого сделать не можем, поскольку процесс обрабатывает только свою часть общего массива данных, то добавляем в третий параметр rdf, являющийся массивом. Каждый параллельный процесс будет заносить в соответствующий ему элемент этого массива локальную дельту, а уже потом центральный процесс на основании этого массива будет вычислять глобальную дельту и принимать решение о продолжении итераций.
В строке 13 мы определяем какой именно процесс из общего количества запущенных выполняется и на основе этого определяется какая именно строка разностной сетки будет обработана.
В 21-ой строке программы мы запрещаем обрабатывать первую и последнюю строки, то есть непосредственно границу сетки.
Так как два слоя двумерной разностной сетки передаются в подпрограмму в виде ссылки на одномерный массив данных, то в строках 24-28 мы вычисляем положение интересующих нас элементов. Иными словами мы отображаем одномерный массив на двумерный.
В строке 37 мы заносим в соответствующий текущему процессу элемент массива rdf вычисленную локальную дельту.
Теперь перейдем к основной программе. Процессы, исполняемые на GPU, не имеют возможности обращаться к основной оперативной памяти компьютера. Поэтому для двух слоев нашей разностной сетки и массива локальных дельт мы определяем и размещаем области памяти GPU. Делается это в строках 67 и 83-85.
Непосредстаенно перед началом цикла итераций и после первоначального заполнения массивов мы должны скопировать данные из оперативной памяти в память графического устройства. Этому действию соответствуют строки 86-88 программы.
Запуск процессов на исполнение осуществляется в строках 92 или 94. В отличие от обычного вызова подпрограммы, запуск с использованием GPU описывается с помощью модификатора <<<BLOCKS, THREADS>>>, в котором указываются сколько ядер мультипроцессора будет задействовано и сколько на каждом из них будет выполняться потоков.
 В действительности это не совсем верно. Параметр BLOCKS указывает не количество задействованных ядер, а количество блоков, каждый из которых будет исполняться на отдельном ядре. Количество таких блоков может быть больше числа ядер GPU. В этом случае эти блоки будут исполнены по мере окончания работы ранее запущенных блоков и освобождения ядер.
В действительности это не совсем верно. Параметр BLOCKS указывает не количество задействованных ядер, а количество блоков, каждый из которых будет исполняться на отдельном ядре. Количество таких блоков может быть больше числа ядер GPU. В этом случае эти блоки будут исполнены по мере окончания работы ранее запущенных блоков и освобождения ядер.
CUDA использует большое число отдельных нитей для вычислений, часто каждому вычисляемому элементами соответствует одна нить. Все нити группируются в иерархию - grid/block/thread. На вершине иерархии находится grid (решетка), которая по сути являюется объединением всех ядер GPU. Блоки (block) - это совокупность отдельных вычислительных процессов, которые выполняются на одном и том же ядре. И наконец thread (нить) - это непосредственно процесс, осуществляющий вычисления.
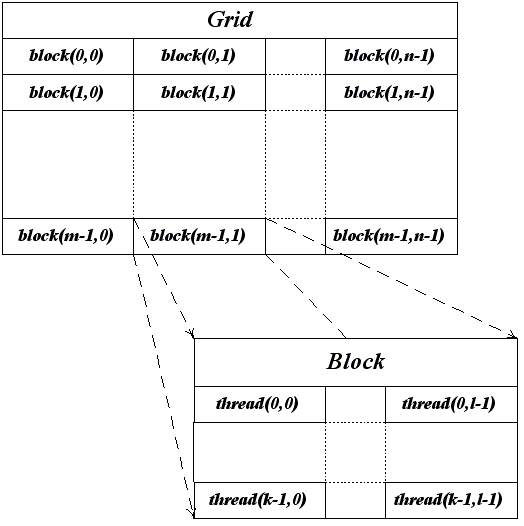
Если программа запрашивает количество блоков меньшее или равное количеству ядер GPU, то все эти блоки и соответствующие им нити процессов будут выполнены одновременно. Если же запрошенное количество блоков превышает размер решетки, то какие-то блоки будут поставлены в очередь до того времени, когда в каком-либо выполняемом блоке все нити будут завершены и этот блок освободит ядро GPU.
В строке 96 мы дожидаемся окончания работы всех запущенных блоков, после чего копируем локальные дельты в оперативную память компьютера (строка 97), вычисляем максимальную для всей разностной сетки дельту (строки 99-101) и принимаем решение о продолжении итераций (строка 103).
И, наконец, после того, как итерационный процесс завершился, мы должны освободить занятую память графического процессора: строки 105-107.
Далее посмотрим, какую выгоду это нам принесло...