
 Regular Domain Decomposition
Regular Domain Decomposition
Очень много задач базируются на обработке больших массивов данных, структурированных в регулярную решетку (матрицу). Как один из многочисленных примеров можно упомянуть численное моделирование газодинамических процессов. В том случае, когда обрабатываемая решетка данных может быть разбита на регулярный (не пересекающийся) массив подрешеток (областей), задача может быть распределена между процессорами кластера и решена в параллельном режиме. Это позволит или сократить время решения задачи, или поставить задачу для более крупныго массива данных (например сделать разностную сетку более мелкой).
Для многих инженерных и научных задач декомпозицияя данных является наиболее подходящим способом подготовить программу для исполнения на параллельной машине. Регулярная декомпозиция исходной решетки может быть проведена в виде смежных кусков, как это представлено на рисунке ниже или каким либо другим, подходящим для задачи образом.
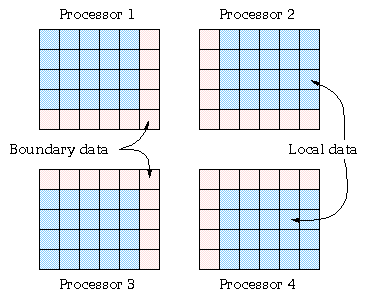
Наибольшая эффективность достигается в случае, когда вычисления производятся в основном локально. Другими словами, когда для изменения ячейки данных требуются информация только из ближайшего окружения. В этом случае вычисления происходят полностью параллельно, а межпроцессорные взаимодействия требуются только для вычисления граничных данных.