Коллективные операции
Коллективные операции
Набор операций типа точка-точка является достаточным для программирования любых алгоритмов, однако MPI вряд ли бы завоевал такую популярность, если бы ограничивался только этим набором коммуникационных операций. Одной из наиболее привлекательных сторон MPI является наличие широкого набора коллективных операций, которые берут на себя выполнение наиболее часто встречающихся при программировании действий. Например, часто возникает потребность разослать некоторую переменную или массив из одного процессора всем остальным. Каждый программист может написать такую процедуру с использованием операций Send/Recv, однако гораздо удобнее воспользоваться коллективной операцией MPI_Bcast. Причем гарантировано, что эта операция будет выполняться гораздо эффективнее, поскольку MPI-функция реализована с использованием внутренних возможностей коммуникационной среды.
Главное отличие коллективных операций от операций типа точка-точка состоит в том, что в них всегда участвуют все процессы, связанные с некоторым коммуникатором. Несоблюдение этого правила приводит либо к аварийному завершению задачи, либо к еще более неприятному зависанию задачи.
Рассмотрим основные функции, определенные для коллективных операций.
Функция синхронизации процессов MPI_Barrier блокирует работу вызвавшего ее процесса до тех пор, пока все другие процессы группы также не вызовут эту функцию. Завершение работы этой функции возможно только всеми процессами одновременно (все процессы "преодолевают барьер" одновременно).
MPI_BARRIER(COMM, IERROR)
INTEGER COMM, IERROR
IN comm - коммуникатор.
Синхронизация с помощью барьеров используется, например, для завершения всеми процессами некоторого этапа решения задачи, результаты которого будут использоваться на следующем этапе. Использование барьера гарантирует, что ни один из процессов не приступит раньше времени к выполнению следующего этапа, пока результат работы предыдущего не будет окончательно сформирован. Неявную синхронизацию процессов выполняет любая коллективная функция.
Широковещательная рассылка данных выполняется с помощью функции MPI_Bcast. Процесс с номером root рассылает сообщение из своего буфера передачи всем процессам области связи коммуникатора comm.
MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERROR)
<type> BUFFER(*)
INTEGER COUNT, DATATYPE, ROOT, COMM, IERROR
| Тип | Параметр | Описание |
|---|---|---|
| INOUT | buffer | адрес начала расположения в памяти рассылаемых данных |
| IN | count | число посылаемых элементов |
| IN | datatype | тип посылаемых элементов |
| IN | root | номер процесса-отправителя |
| IN | comm | коммуникатор |
После завершения подпрограммы каждый процесс в области связи коммуникатора comm, включая и самого отправителя, получит копию сообщения от процесса-отправителя root.
Пример использования функции MPI_Bcast.
... IF ( MYID .EQ. 0 ) THEN PRINT *, 'ВВЕДИТЕ ПАРАМЕТР N : ' READ *, N END IF CALL MPI_BCAST(N, 1, MPI_INTEGER, 0, MPI_COMM_WORLD, IERR)
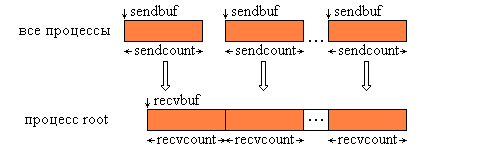
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми процессами группы, в один массив процесса с номером root. Длина блоков предполагается одинаковой. Объединение происходит в порядке увеличения номеров процессов-отправителей. То есть данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf процесса root. Длина массива, в который собираются данные, должна быть достаточной для их размещения.
MPI_GATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF,
RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR
| Тип | Параметр | Описание |
|---|---|---|
| IN | sendbuf | адрес начала размещения посылаемых данных |
| IN | sendcount | число посылаемых элементов |
| IN | sendtype | тип посылаемых элементов |
| OUT | recvbuf | адрес начала буфера приема (используется только в процессе-получателе root) |
| IN | recvcount | число элементов, получаемых от каждого процесса (используется только в процессе-получателе root) |
| IN | recvtype | тип получаемых элементов |
| IN | root | номер процесса-получателя |
| IN | comm | коммуникатор |
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число sendcount должно равняться числу recvcount. То есть, recvcount в вызове из процесса root - это число собираемых от каждого процесса элементов, а не общее количество собранных элементов.
Графическая интерпретация операции Gather представлена на следующем рисунке:
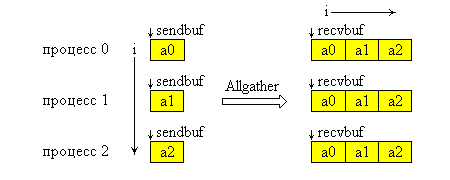
Функция MPI_Allgather выполняется так же, как MPI_Gather, но получателями являются все процессы группы. Данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf каждого процесса. После завершения операции содержимое буферов приема recvbuf у всех процессов одинаково.
MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF,
RECVCOUNT, RECVTYPE, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMM, IERROR
| Тип | Параметр | Описание |
|---|---|---|
| IN | sendbuf | адрес начала буфера посылки |
| IN | sendcount | число посылаемых элементов |
| IN | sendtype | тип посылаемых элементов |
| OUT | recvbuf | адрес начала буфера приема |
| IN | recvcount | число элементов, получаемых от каждого процесса |
| IN | recvtype | тип получаемых элементов |
| IN | comm | коммуникатор |
Графическая интерпретация операции Allgater представлена на следующем рисунке. На этой схеме ось Y образуют процессы группы, а ось X блоки данных.
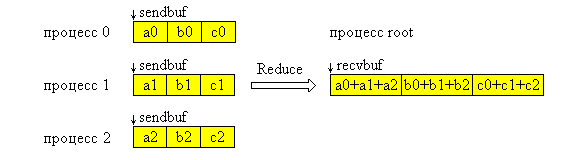
Функция MPI_Reduce выполняется следующим образом. Операция глобальной редукции, указанная параметром op, выполняется над первыми элементами входного буфера, и результат посылается в первый элемент буфера приема процесса root. Затем то же самое делается для вторых элементов буфера и т.д.
MPI_REDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, ROOT,
COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, ROOT, COMM, IERROR
| Тип | Параметр | Описание |
|---|---|---|
| IN | sendbuf | адрес начала входного буфера |
| OUT | recvbuf | адрес начала буфера результатов (используется только в процессе-получателе root) |
| IN | count | число элементов во входном буфере |
| IN | datatype | тип элементов во входном буфере |
| IN | op | операция, по которой выполняется редукция |
| IN | root | номер процесса-получателя результата операции |
| IN | comm | коммуникатор |
Ниже на рисунке представлена графическая интерпретация операции Reduce. На данной схеме операция "+" означает любую допустимую операцию редукции.