
 Нужно ли делать кластер?
Нужно ли делать кластер?
Если вы не хакер и не фанат компьютерных технологий, то построение кластерного компьютера не самоцель, а средство достигнуть большей эффективности и продуктивности вашей научной работы. Cуществуют определенный класс задач, требующих производительности более высокой, нежели мы можем получить, используя обычные компьютеры. В этих случаях из нескольких мощных систем создают HPC (High Perfomance Computing) кластер, позволяющий разнести вычисления не только по разным процессорам (если используются многопросерросные SMP-системы), но и по разным компьютерам. Для задач, позволяющих очень хорошее распараллеливание и не предъявляющих высоких требований по взаимодействию параллельных потоков, часто принимают решение о создании HPC кластера из большого числа маломощных однопроцессорных систем. Зачастую подобные решения, при низкой стоимости, позволяют достичь гораздо большей производительности, чем производительность суперкомпьютеров.

Однако, создание такого кластера требует определенных знаний и усиилий, а использование его влечет за собой кардинальную смену используемой парадигмы программирования, что психологически достаточно трудно. Вы можете быть крутым специалистом в написании последовательных программ, но это не спасет вас от необходимости изучения методов параллельного программирования, возможно, начиная даже с самых азов.
Часто можно встретить заблуждение, что только использование суперкомпьютера может само по себе дать прирост производительности. Это не верно. Если ваша задача не имеет внутреннего параллелизма и не адаптирована соответствующим образом, максимум, что вы можете получить от кластера -- это запуск на выполнение нескольких экземпляров программы одновременно, работающих с различными начальными данными. Это не ускорит выполнение одной конкретной программы, но позволит сэкономить много времени, если необходимо посчитать множество вариантов за ограниченное время. Можно привести следующую аналогию: один корабль переплывает море за 7 дней, но семь кораблей не смогут переплыть море за день. За то, они смогут перевезти за неделю в 7раз больше груза. Если объемы вашей задачи таковы, что только один прогон на однопроцессорной машине может длиться сутками, неделями и месяцами, то очевидно, следует приложить усилия по адаптации алгоритма. Следует разделить задачу на несколько (по числу процессоров) более мелких подзадач, которые могут выполняться независимо, а в тех местах, где независимое выполнение невозможно, явно вызывать процедуры синхронизации, для обмена данными через сеть. Например, если вы обрабатываете большой массив данных, то разумно будет разделить его на области и распределить их по процессорам, обеспечив равномерную загрузку всего кластера.
Поэтому прежде чем перейти к практической реализации кластерной технологии необходимо решить для себя несколько принципиальных вопросов.
Первый из них звучит так: "Необходим ли для решения моих задач кластер и параллельные вычисления?" Чтобы ответить на этот вопрос надо внимательно присмотреться к решаемым вами задачам. Параллельные вычисления - достаточно специфичная область математики и далеко не всегда параллельные вычисления могут быть вами применимы. Кластер вам скорее всего не нужен, если:
- Вы используете специализированные пакеты программ, которые не адаптированы для параллельных вычесление в средах MPI и PVM или не предназначенные для работы в UNIX. В этом случае вы просто не сможете задействовать долее одного процессора для выполнения задачи или вообще запустить вашу программу в чужой операционной среде.
- Программы, написанные вами для решения ваших задач, требуют не более нескольких часов процессорного времени на имеющемся оборудовании. Может случиться так, что время, потраченное вами на распараллеливание и отладку вашей задачи съест все преимущество в быстродействии, которое даст многопроцессорная обработка.
- Время жизни вашей программы сравнимо со временем ее разработки в параллельном варианте. Основными особенностями модели параллельного программирования являются высокая эффективность программ, применение специальных приемов программирования и, как следствие, более высокая трудоемкость программирования. Не имеет смысла тратить время на распараллеливание программы, которая будет считаться несколько часов один раз в жизни, после чего, получив результаты, вы про нее забудете.
Второй вопрос, который вы должны решить, это наличие принципиальной возможности "распараллелить" вашу задачу. Некоторые численные схемы в силу особенностей алгоритма не поддаются эфективной параллелезиции. Прежде чем ориентироваться на применение кластера для для решения вашей задачи, необходимо удостовериться в возможности применения вами паралельных алгоритмов.
Приложение в параллельной архитектуре должно создаваться с расчетом на эффективное использование ресурсов этой архитектуры. Под этим понимается то, что приложение должно быть разделено на части, способные исполняться параллельно на нескольких процессорах, и разделено эффективно, чтобы отдельно исполняемые куски программы минимально влияли на исполнение остальных частей.
Предположим, что в вашей программе доля операций, которые нужно выполнять последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в значениях f соответствуют полностью параллельным (f=0) и полностью последовательным (f=1) программам. Так вот, для того, чтобы оценить, какое ускорение S может быть получено на компьютере из p процессоров при данном значении f, можно воспользоваться законом Амдала:
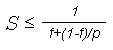
Если вдуматься как следует, то закон, на самом деле, страшный. Предположим, что в вашей программе лишь 10% последовательных операций, т.е. f=0.1 . Что утверждает закон? А он говорит о том, что сколько бы вы процессоров не использовали, ускорения работы программы более, чем в десять раз никак не получите... да и то 10 - это теоретическая верхняя оценка самого лучшего случая, когда никаких других отрицательных факторов нет... :((
Отсюда первый вывод - прежде, чем основательно перепахивать код для перехода на параллельный компьютер надо основательно подумать, а стоит ли овчинка выделки?. Если оценив заложенный в программе алгоритм вы поняли, что доля последовательных операций велика, то на значительное ускорение рассчитывать явно не приходится и нужно думать о замене отдельных компонент алгоритма.
В дополнение к вышесказанному настоятельно рекомендуется прочесть и осознать вот эти замечания.
Трудовые затраты на распараллеливание или векторизацию программы
Самый простой вариант попробовать ускорить имеющуюся программу - это воспользоваться встроенными в транслятор (обычно с ФОРТРАНа или Си) средствами векторизации или распараллеливания. При этом никаких изменений в программу вносить не придется. Однако вероятность существенного ускорения (в разы или десятки раз) невелика. Трансляторы с ФОРТРАНа и Си векторизуют и распараллеливают программы очень аккуратно и при любых сомнениях в независимости обрабатываемых данных оптимизация не проводится. Поэтому, кстати, и не приходится ожидать ошибок от компиляторов, если программист явно не указывает компилятору выполнить векторную или параллельную оптимизацию какой-либо части программы.
Второй этап работы с такой программой - анализ затрачиваемого времени разными частями программы и определение наиболее ресурсопотребляющих частей. Последующие усилия должны быть направлены именно на оптимизацию этих частей. В программах наиболее затратными являются циклы и усилия компилятора направлены прежде всего на векторизацию и распараллеливание циклов. Диагностика компилятора поможет установить причины, мешающие векторизовать и распараллелить циклы. Возможно, что простыми действиями удастся устранить эти причины. Это может быть простое исправление стиля программы, перестановка местами операторов (цикла и условных), разделение одного цикла на несколько, удаление из критических частей программы лишних операторов (типа операторов отладочной печати). Небольшие усилия могут дать здесь весьма существенный выигрыш в быстродействии.
Третий этап - замена алгоритма вычислений в наиболее критичных частях программы. Способы написания оптимальных (с точки зрения быстродействия) программ существенно отличаются в двух парадигмах программирования - в последовательной и в параллельной (векторной). Поэтому программа, оптимальная для скалярного процессора, с большой вероятностью не может быть векторизована или распараллелена. В то же время специальным образом написанная программа для векторных или параллельных ЭВМ будет исполняться на скалярных машинах довольно медленно. Замена алгоритма в наиболее критических частях программы может привести к серьезному ускорению программы при относительно небольших потраченных усилиях. Дополнительные возможности предоставляют специальные векторные и параллельные библиотеки подпрограмм. Используя библиотечные функции, которые оптимизированы для конкретной ЭВМ, можно упростить себе задачу по написанию и отладке программы. Единственный недостаток данного подхода состоит в том, что программа может стать не переносимой на другие машины (даже того же класса), если на них не окажется аналогичной библиотеки.
Написание программы "с нуля" одинаково сложно (или одинаково просто) для машин любых типов. Этот способ является идеальным для разработки эффективных, высокопроизводительных векторных или параллельных программ. Начинать надо с изучения специфики программирования для векторных и параллельных ЭВМ, изучения алгоритмов, которые наиболее эффективно реализуются на ЭВМ данных типов. После этого надо проанализировать поставленную задачу и определить возможность применения векторизуемых и распараллеливаемых алгоритмов для решения конкретной задачи. Возможно, что придется переформулировать какие-то части задачи, чтобы они решались с применением векторных или параллельных алгоритмов. Программа, специально написанная для векторных или параллельных ЭВМ, даст наибольшее ускорение при ее векторизации и распараллеливании.