
 Сетка процессов
Сетка процессов
Метод регулярной декомпозиции сосотоит в разбиении исходной большой сетки данных на непересекающиеся регулярные области (подсетки) и распределении этих подсеток между процессорами, где эти части данных могут быть параллельно обработаны. Другими словами глобальный набор данных декомпозируется на секции и каждая секция передается под контроль отдельного процесса так, как это показано на следующем рисунке.
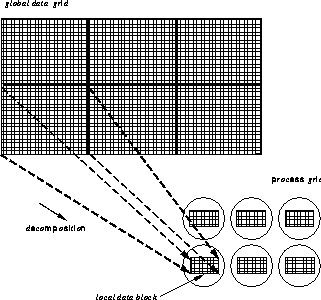 Перед тем, как сетка данных будет рапределена между процессами, сами процессы должны быть организованы в логическую структуру, соотвествующую структуре данных. Другими словами процессы не являются копиями одной и той же программы, хотя и могут выполнять одинаковые по сути действия. Каждый процесс должен, во-первых, учитывать какого типа данные он обрабатывает. В том же примере с газодинамикой процессы можно разделить на те, которые вычисляют плотность, скорость или гравитацию. Во-вторых, процесс должен учитывать откуда берутся данные, из центра глобальной сетки или с ее края. Набор данных, распределенных процессу в дальнейшем будем называть блоком данных этого процесса.
Перед тем, как сетка данных будет рапределена между процессами, сами процессы должны быть организованы в логическую структуру, соотвествующую структуре данных. Другими словами процессы не являются копиями одной и той же программы, хотя и могут выполнять одинаковые по сути действия. Каждый процесс должен, во-первых, учитывать какого типа данные он обрабатывает. В том же примере с газодинамикой процессы можно разделить на те, которые вычисляют плотность, скорость или гравитацию. Во-вторых, процесс должен учитывать откуда берутся данные, из центра глобальной сетки или с ее края. Набор данных, распределенных процессу в дальнейшем будем называть блоком данных этого процесса.
На каждой итерации, каждый процесс берет на себя работу по изменению значений элементов данных, которые содержатся в его локальном блоке данных. Вычисляя новое значение элемента, процесс выполняет некоторые калькуляции, основываясь на старом (старых) значении этого элемента и возможно также на старых значениях элементов, находящихся в некоторой близости от обрабатываемого элемента.
При вычислении нового значения элемента, может сложиться такая ситуация, когда не все необходимые для вычисления соседи находятся в локальном блоке данных процесса. Для доступа к элементам из других блоков данных каждый процесс должен иметь "теневую" область на которую из соседних процессов отображаются элементы, окружающие локальный для данного процесса блок данных.
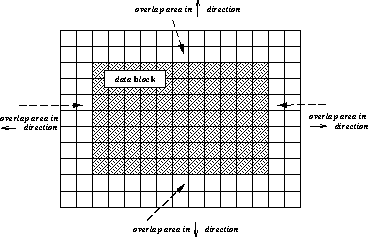
Элементы в теневой области должны быть доступны для процесса в режиме "только чтение". Такие теневые области называются областями перекрытия. Локальный блок данных окруженный областью перекрытия мы будем называть массивом данных. Надо заметить, что массив данных процесса не обязательно должен иметь области перекрытия одинаковой толщины по всем направлениям. В некоторых случаях область перекрытия может отсутствовать по одному, нескольким или всем направлениям или иметь разную толщину по разным направлениям. Также, форма области перекрытия может отличаться у разных процессов. Толщина области перекрытия для каждого процесса определяется особенностями выбранного численного алгоритма.
Поскольку изменение значения пограничного эелемента локального блока данных процесса требует наличия элементов в области перекрытия, каждый процесс должен быть готов послать копию граничных элементов своего локального блока данных процессу, которому эти данные необходимы. Аналогично, каждый процесс должен быть в состоянии принять копии элементов от соседних процессов в свою область перекрытия.
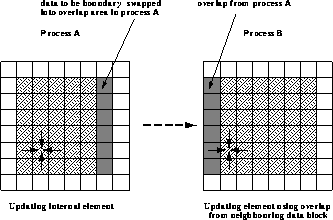 На следующем рисунке показаны два процесса A и B. Процесс A выполняет изменение значения элемента (отмеченного стрелками), который находится далеко от границы и, таким образом, значения элементов области перекрытия для вычисления не используются. Процесс B выполняет обработку элемента, для изменения значения которого требуется значения элементов из области перекрытия с процессом A. Процесс A должен выполнить граничный обмен с процессом B до того момента, когда процессу B понадобится обратиться к элементам в области перекрытия.
На следующем рисунке показаны два процесса A и B. Процесс A выполняет изменение значения элемента (отмеченного стрелками), который находится далеко от границы и, таким образом, значения элементов области перекрытия для вычисления не используются. Процесс B выполняет обработку элемента, для изменения значения которого требуется значения элементов из области перекрытия с процессом A. Процесс A должен выполнить граничный обмен с процессом B до того момента, когда процессу B понадобится обратиться к элементам в области перекрытия.
Следует отметить, что чем шире оказываются области перекрытия, тем менее эффективным становится распараллеливание программ методом регулярной декомпозиции, поскольку процесс граничного обмена будет занимать все более длительный промежуток времени. Однако, это зависит от соотношения времен страничного обмена и собственно счета одной итерации. Если процесс итерации достаточно длителен, то граничный обмен даже при максимально больших областях перекрытия может слабо тормозить вычисления.
Под детелизацией понимается степень востребованности данных из области перекрытия при обработке элементов глобального блока данных. В случае, когда вычисление каждого элемента глобального блок данных требует от процессов доступа к областям перекрытия, мы имеем высокую степень детализации (fine granularity). В случае, когда ни один элемент из глобального блока данных при его обработке процессами не требует доступа в области перекрытия или таковые отсутствуют, мы имеем грубую степень детализации (coarse granularity).
Чем выше степень детализации, тем менее эффективным становится параллельный процесс. Степень детализации определяется как типом выбранного для решения задачи численного алгоритма, так и количеством процессов на которое мы раздробим исходную задачу.
Если применяемый численный алгоритм требует при калькуляции доступа к соседним элементам, то увеличение количества процессов (увеличение степени дробления исходной сетки данных) увеличивает объем областей перекрытия и, соответственно, количество элементов, при обработке которых требуется доступ к этим областям. Таким образом, увеличение количества параллельных процессов увеличивает степень детализации. Наступает определенный момент, когда приращение эффективности параллельной задачи за счет увеличения количества процессов станет меньше, чем снижение эффективности из-за увеличения степени детализации.
Как уже кратко было упомянуто, часто бывает необходимо для вычисления нового значения элемента данных (проведения итерации) организовать в одном из процессов доступ к данным, полученным в результате работы другого процесса.
Когда значение какого-то элемента данных изменяются, новое значение этого элемента может зависить как от старого значения, так и от старых значений некоторго количества соседних элементов, часть из которых может находится в локальном блоке данных другого процесса. В этом случае копии таких элементов должны быть переданы в процесс из других процессов. С другой стороны, процесс должен быть готов к передаче результатов своей работы процессам, которым эти данные могут понадобится для проведения следующей итерации.
Таким образом для процессов можно предложить следующий алгоритм выполнения итераций:
- посылаем собственные данные процессам, которым они могут понадобится для проведения следующей итерации
- принимаем данные от соседних процесов для заполнения собственной области перекрытия новыми значениями.
- выполняем обработку данных (выполняем итерацию)
Процесс посылки и приема данных от других процессов называется "граничный обмен".